数据同步
数据同步 任务提供两种模式进行选择
向导模式
向导模式的特点是便捷、简单,可视化字段映射,快速完成同步任务配置,无需关心chunjun的json格式,但需要针对每种数据源进行适配开发
新建任务
进入"开发目录"菜单,点击"新建任务"按钮,并填写新建任务弹出框中的配置项,配置项说明:
- 任务名称:需输入英文字母、数字、下划线组成,不超过64个字符
- 任务类型:选择数据同步
- 存储位置:在页面左侧的任务存储结构中的位置
- 描述:长度不超过200个的任意字符 点击"保存",弹窗关闭,即完成了新建任务
同步模式
标识本任务是否采用增量模式,无增量标识:可通过简单的过滤语句实现增量同步;有增量标识:系统根据源表中的增量标识字段值,记录每次同步的点位,执行时可从上次点位继续同步
任务配置
数据同步任务的配置共分为5个步骤:
- 选择数据来源:选择已配置的数据源,系统会读取其中的数据
- 选择数据目标:选择已配置的数据源,系统会向其写入数据
- 字段映射:配置数据来源与数据目标之间的字段映射关系,不同的数据类型在这步有不同的配置方法
- 通道控制:控制数据同步的执行速度、错误数据的处理方式等
- 预览保存:再次确认已配置的规则并保存
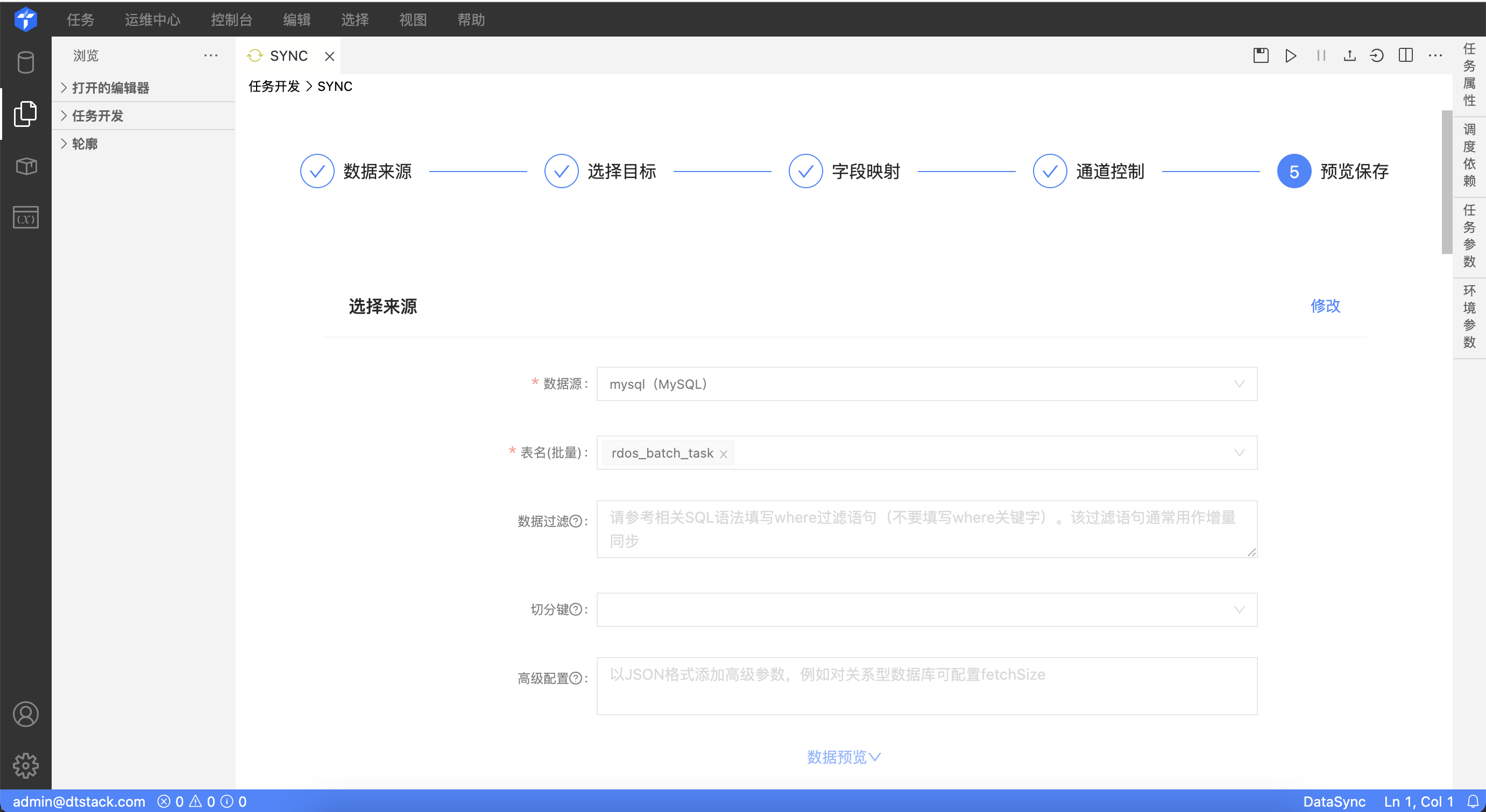
数据源/目标配置
关系型与MPP型数据库
关系型数据库与MPP数据库涵盖以下数据源: MySQL、Oracle、PostgreSQL
Reader 关系型数据库或MPP型数据库作为数据源,需配置以下信息:
- 数据源
- 表
- 数据过滤:针对源头数据筛选条件,根据指定的column、table、where条件拼接SQL进行数据抽取,暂时不支持limit关键字过滤。利用where条件可进行增量同步,具体说明如下:
增量导入在实际业务场景中,往往会选择当天的数据进行同步,通常需要编写where条件语句,需先确认表中描述增量字段(时间戳)为哪一个。如
tableA增量的字段为create_time,则填写create_time>需要的日期,如果需要日期动态变化,可以填写${bdp.system.bizdate}、${bdp.system.cyctime}等调度参数,关于调度参数的详细信息请参考 [参数配置]。 - 切分键:离线开发在进行数据抽取时,如果指定切分键,系统可以使用切分键的字段进行数据分片,数据同步因此会启动并发任务进行数据同步,这样可以大大提供数据同步的效能。
- 推荐将表的主键作为切分键,因为表主键通常情况下比较均匀,因此切分出来的分片也不容易出现数据热点。
- 目前离线开发目前支持MySQL、Oracle、SQLServer、PostgreSQL、DB2、GBase 8a、达梦、PolarDB for MySQL8、Phoenix、Greenplum,仅支持数值型字段作为切分键,不支持字符串、浮点、日期等其他类型。如果指定了不支持的类型,则忽略切分键功能,使用单通道进行同步
- 如果在第四步的「作业并发数」大于1但是没有配置切分键,任务将置为失败
- 如果不填写切分键,数据同步视作使用单通道同步该表数据
- 切分键的配置需要与第四步的
通道控制联合使用,下面是典型的应用场景: 假设MySQL的tableA表中,有一个INT类型的字段名为id的主键,那么可以在切分键输入框中输入id字段,并在第四步的"作业并发数"中配置为5,则系统会产生5个并发线程同时读取MySQL表,每个任务会根据id字段的值进行数据切分,保证5个并发线程读取的数据是不同的,通过以上机制即可以加速数据读取的速度。
- 高级配置:特定场景下,无法满足需求时,支持以JSON的形式传入其他参数,例如fetchSize等。
tip
关系型数据库设置作业速率上限和切分键才能根据作业速率上限将表进行切分,只支持数值型作为切分键
Oracle读取/写入其他Schema下的表
tip
Oracle通过用户名来标识Schema,如果需要同步其他Schema下的数据,则不能在下拉列表中选择表,而是直接输入schemaName.tableName,可读取/写入其他Schema的数据
Writer 关系型数据库作为数据目标,需配置以下信息:
- 数据同步目标库;
- 目标表;
- 导入前、导入后准备语句:执行数据同步任务之前率先执行的SQL语句。目前向导模式只允许执行一条SQL语句,例如:
truncate table。 - 主键冲突的处理:
- insert into:当主键/唯一性索引冲突时会写不进去冲突的行,以脏数据的形式体现,脏数据的配置与管理请参考 [脏数据管理];
- replace into:没有遇到主键/唯一性索引冲突时,与insert into行为一致,冲突时,先delete再insert,未映射的字段会被映射为NULL;
- on duplicate key update:当主键/约束冲突,update数据,未映射的字段值不变;
字段映射 请参考[字段映射的通用功能]
MySQL分库分表
tip
目前分库分表模式仅支持MySQL数据源,其他数据源暂不支持 mysql分库分表实际是把表结构完全相同的多张表同步到一张目标表里。所以在数据预览的时候只默认显示第一张表的数据样例。所有数据同步任务都实际只支持单张表的同步(MySQL分库分表是特殊),不存在多张表同步到多张表的同步功能。
同一个同步任务,可以同时并发(或串行)读取多个库、多个表,适用于业务库采用了分库分表的情况下,配置方式比较简单,仅需在同一个同步任务中添加多个库、多个表即可。 在页面上勾选「批量选择」,还可以支持按表名搜索、批量选中等操作,便于对大量表配置数据同步。 分库分表的一些限制条件:
- 选中的库、表,表结构需要保持一致(字段名、字段类型),系统不会进行检查,表结构的一致性由用户保证;
- 若MySQL采用分库模式,则不同的数据库需配置不同的数据源,需要在「数据源」模块单独配置;
- 若配置了并发度,则每个并发会分别读取一张表的数据;
tip
仅支持MySQL分库分表数据的读取,不支持写入
caution
数据同步仅支持关系型数据库的普通数据类型,暂时不支持blob、clob、地理空间等特殊类型的数据读/写
大数据存储型
Hive1.x / Hive 2.x
- Hive1.x与Hive2.x的配置是基本相同的,详情请参考 [Hive1.x与Hive2.x的区别]
- Hive1.x与Hive2.x仅支持Textfile、ORC、Parquet 这3种数据格式,同步的原理请参考 [FlinkX读写Hive表的原理]
Reader
- 分区:当Hive表作为数据源时,可读取某个分区下的数据:
- 分区填写栏支持填写参数,支持的参数请参考 [参数配置]
- 非分区表,不用填写;
- 一级分区表,不填写分区,则会读取所有分区数据;填写了分区名(例如
pt = '20200503'),则只读取指定分区的数据; - 多级分区表,可以填写多级分区形式(例如
ptd='20200503' /pdh='120000'),多级分区表,如果只填写一级分区信息(例如ptd='20200503'),则会将下属的所有二级分区数据全部读取;
Writer
- 分区:当Hive表作为写入目标时,可将数据写入某个分区:
- 分区填写栏支持填写参数,支持的参数请参考 [参数配置]
- 动态分区机制:当写入的分区名不存在时,系统按用户指定的分区名自动创建
- 对于非分区表,无需填写;
- 一级分区表,必须填写(例如
pt = '20200503') - 多级分区表,必须填写至最末一级分区(例如
ptd='20200503' /pdh='120000')
- 写入模式:
- insert overwrite:写入前将清理已存在的数据文件,之后执行写入(默认值);
- insert into:写入前已有的数据不会删除,系统会写入的新的文件;
tip
不支持路由写入,对于分区表请务必保证写入数据到最末一级分区(HDFS上一个确定的目录)
字段映射
在支持向导模式配置的数据源中,均需要配置字段映射,标识源表与目标表之间每个字段的映射关系。离线开发仅支持「基本功能」中的format转换,不支持其他类型的数据转换功能,不建议在数据传输过程中进行过多的转换,而是在落盘后再转换
基本功能
离线开发所支持的任意数据源、目标之间,字段映射模块支持以下基本功能:
- 支持选择部分字段进行读取/写入。
- format处理:数据源为字符串类型的字段,若存储了日期数据,且映射到目标库的date或time等时间类型,支持指定format格式,例如
"yyyy-MM-dd hh:mm:ss,若不配置此转换规则,则此数据可能被认为是脏数据。format处理支持Java格式化时间的标准格式,可参考 [SimpleDateFormat]。 - 支持在数据源一侧添加常量/系统变量作为虚拟字段值,请参考[虚拟字段]。
caution
在配置字段映射时,建议检查源表、目标表之间的字段类型映射关系,建议将目标表的字段类型统一设置为string,并在下游数据加工任务中进行类型转换,提高数据同步环节的可靠性,尤其是写入Hive表
连线映射
在源表和目标表的字段之间连线,标识对应的2个字段的映射关系,离线开发目前仅支持一一映射,不支持一对多,或多对一映射。虽然可以手动连线,但建议用户采用同名映射或同行映射,便于快速配置。
同名与同行映射
按照字段名,或者左右两侧的字段序号进行映射匹配,再次点击可取消映射关系。
虚拟字段
支持在数据源端增加虚拟字段,作为附加信息写入到目标端
tip
虚拟字段必须被映射至结果表,否则不会生效
常量字段
当需要添加某个常量信息至结果表时,可使用虚拟字段的常量字段功能,点击「添加常量」按钮,在弹窗中的「常量值」文本框中输入,例如 shanghai(注意无需输入引号),则此字符串常量将会被写入目标端的指定字段
变量字段
这里的变量字段指的是系统的调度参数,点击「添加常量」按钮,在「常量值」文本框中输入系统变量(变量名称需单独填写),例如${bdp.system.bizdate},则系统将根据周期调度中系统变量的取值作为此字段的值。对于变量字段,同样可以将此字段的内容进行format处理,format处理请参考本页的[基本功能]。
通道控制
同步速率与作业并发
- 作业速率上限
设置作业速率上限,则数据同步作业的总速率将尽可能按照这个上限进行同步,此参数需根据实际数据库情况调整,默认为不限制,页面可选择1-20MB/s,也可以直接填写希望的数值。当数据量较大,且硬件配置较好时,可以提高作业速率上限,离线开发将会提高同步速度,使用较短的时间完成同步。
tip
流量度量值是数据集成本身的度量值,不代表实际网卡流量,实际流量膨胀看具体的数据存储系统传输序列化情况
- 作业并发数
caution
仅关系型或MPP类数据库才支持作业并发数,具体支持的数据库类型请参考[关系型与MPP型数据库]
作业并发数需要与「数据源」配置中的「切分键」联合发挥作用,系统将一张表的数据切分多个通道并发读取,提高同步速度,如果作业并发数大于1但是没有配置切分键,任务将置为失败。
作业速率上限=作业并发数*单作业的传输速率,当作业速率上限已定,选择的并发数越高则单并发的速率越低,同时所占用的内存会越高,这可以根据业务需求选择设定的值。
- 断点续传
断点续传的基本原理请参考 [断点续传],对标识字段的要求如下:
- 数据源(这里特指关系数据库)中必须包含一个升序的字段,比如主键或者日期类型的字段,同步过程中会记录同步的点位,任务在中途发生异常失败,在恢复运行时使用这个字段构造查询条件过滤已经同步过的数据,如果这个字段的值不是升序的,那么任务恢复时过滤的数据就是错误的,最终导致数据的缺失或重复;
- 用户需保证此字段的值是数据升序的;
脚本模式
脚本模式的特点是全能、高效,可深度调优,支持全部数据源,完全兼容chunjun的json格式.
脚本配置
| 数据库 | 源(读取) | 目标(写入) |
|---|---|---|
| MySQL | doc | doc |
| TiDB | 参考MySQL | 参考MySQL |
| Oracle | doc | doc |
| SqlServer | doc | doc |
| PostgreSQL | doc | doc |
| DB2 | doc | doc |
| ClickHouse | doc | doc |
| Greenplum | doc | doc |
| KingBase | doc | doc |
| MongoDB | doc | doc |
| SAP HANA | doc | doc |
| ElasticSearch7 | doc | doc |
| FTP | doc | doc |
| HDFS | doc | doc |
| Stream | doc | doc |
| Redis | 不支持 | doc |
| Hive | 参考HDFS | doc |
| Solr | doc | doc |
| File | doc | 不支持 |
同步任务参数
在同步任务的「环境参数」中,运行方式(flinkTaskRunMode)参数较为重要,任务运行方式有2种:
- per_job:单独为任务创建flink yarn session,任务运行的资源有保障,提高任务运行稳定性
- session:多个任务共用一个flink yarn session,默认session,适合小数据量同步,节约集群资源
设置方式,在任务的「环境参数」中,修改/添加此参数
## flinkTaskRunMode=new,其中 ##标识为注释状态,用户需要取消注释才能生效
任务配置
环境参数
## 任务运行方式:
## per_job:单独为任务创建flink yarn session,适用于低频率,大数据量同步
## session:多个任务共用一个flink yarn session,适用于高频率、小数据量同步,默认session
## flinkTaskRunMode=per_job
## per_job模式下jobManager配置的内存大小,默认1024(单位M)
## jobmanager.memory.mb=1024
## per_job模式下taskManager配置的内存大小,默认1024(单位M)
## taskmanager.memory.mb=1024
## per_job模式下每个taskManager 对应 slot的数量
## slots=1
## checkpoint保存时间间隔
## flink.checkpoint.interval=300000
## 任务优先级, 范围:1-1000
## job.priority=10
tip
右侧任务参数有数据同步的默认参数信息 可以手动调整数据同步的运行模式以及slot数量等参数
数据同步同步任务默认为session模式
向导模式支持的数据源
数据源
- MySQL
- ORACLE
- POSTGRESQL
- HIVE
- SPARK THRIFT
写入源
- MySQL
- ORACLE
- POSTGRESQL
- HIVE
- SPARK THRIFT
caution
数据同步 依赖控制台 Flink组件 运行数据同步前请确保对应组件配置正确