Hadoop MR
1. 任务界面
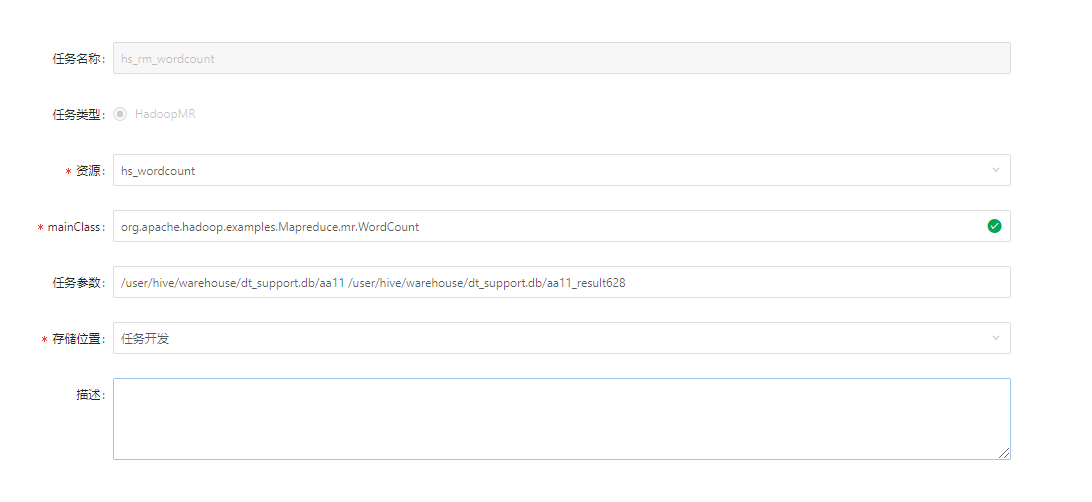
2. 传参
//函数的传参,与命令行方式一致的参数列表【输入路径和输出路径】,例如
/user/hive/warehouse/dt_support.db/aa11 /user/hive/warehouse/dt_support.db/aa11_result628
3. 示例代码1(main函数参数列表第一位必须为Configuration)
package org.apache.hadoop.examples.Mapreduce.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
import java.util.StringTokenizer;
public class WordCount
{
//conf值由Taier平台管理
//job.submit 提交后需要返回jobId,返回类型为String
public static String main(Configuration conf,String[] args) throws Exception
{
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; i++) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[(otherArgs.length - 1)]));
job.submit();
return job.getJobID().toString();
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
this.result.set(sum);
context.write(key, this.result);
}
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
}
4. 已有MR任务集成到Taier,改动仅两步
4.1修改pom.xml文件
首先把pom.xml文件导入
<?xml version="1.0" encoding="UTF-8"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-examples</artifactId>
<version>2.7.3</version>
<description>Apache Hadoop MapReduce Examples</description>
<name>Apache Hadoop MapReduce Examples</name>
<packaging>jar</packaging>
<properties>
<mr.examples.basedir>${basedir}</mr.examples.basedir>
<project.version>2.7.3</project.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${project.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>${project.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>${project.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${project.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${project.version}</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>utf-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass>org.apache.hadoop.examples.Mapreduce.mr.WordCount</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
</project>
4.2调整代码
4.2.1修改main方法列表,代码中使用参数列表中的conf
修改前:
public static void main(String[] args) throws Exception
{
Configuration conf =new Configuration();
修改后:
public static String main(Configuration conf,String[] args) throws Exception
{
4.2.2job.submit 并返回 jobId
修改前:
System.exit(job.waitForCompletion(true) ? 0 : 1);
修改后:
job.submit();
return job.getJobID().toString();