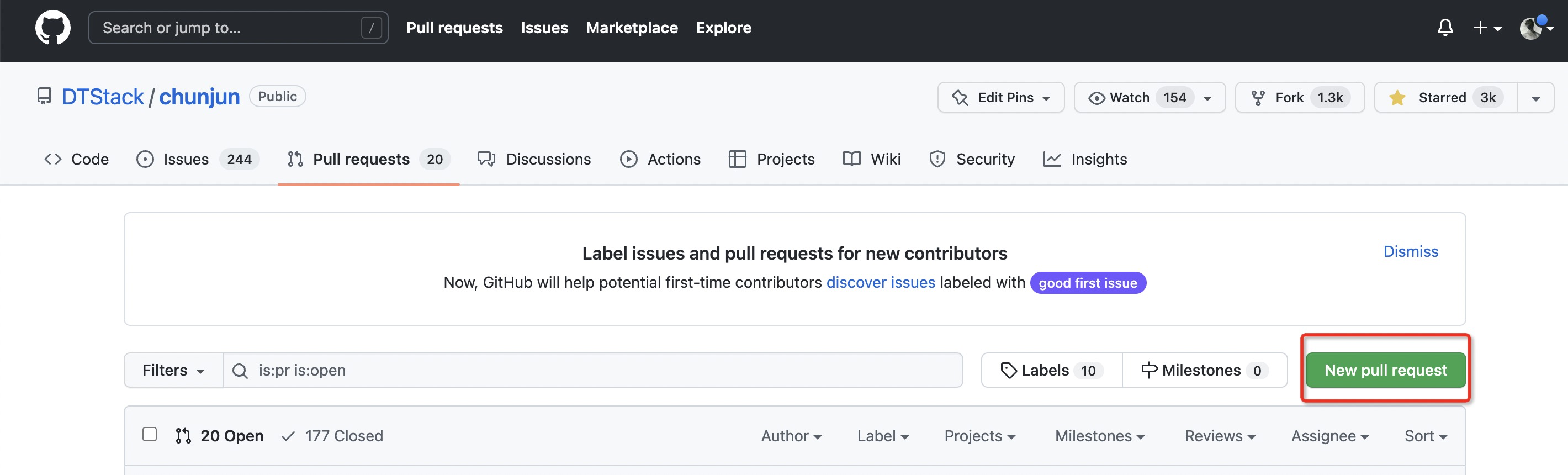
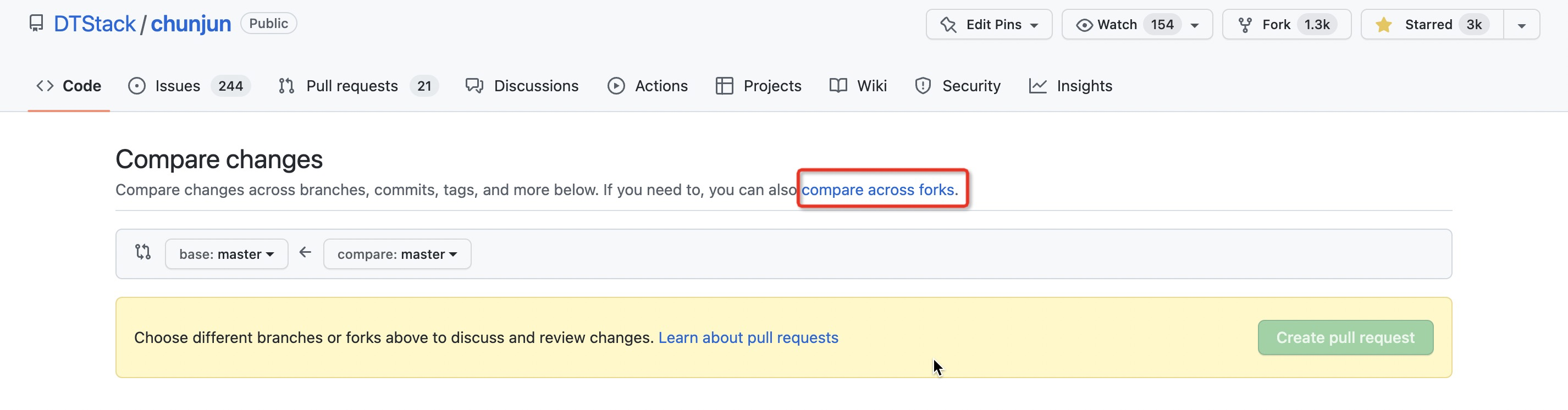
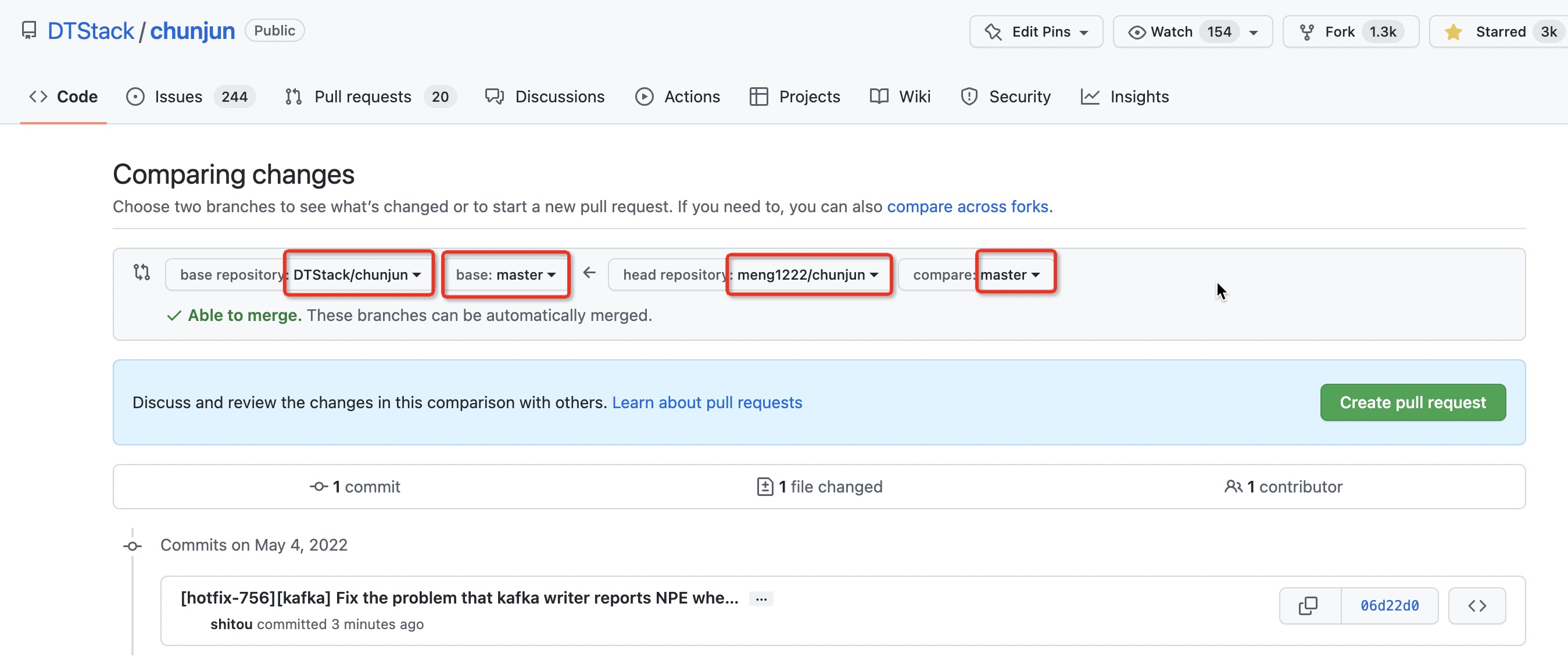
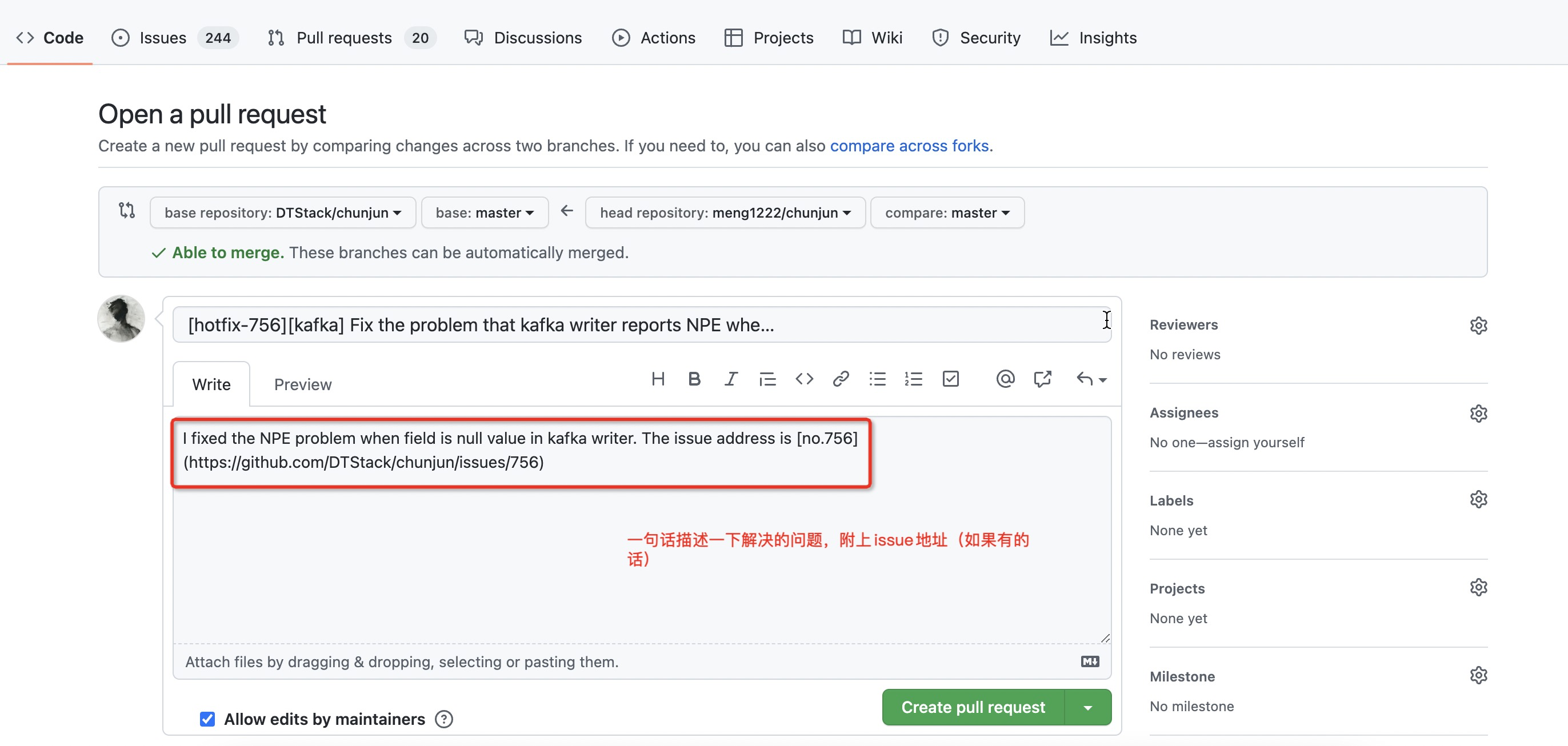
如何自定义插件
本文面向 ChunJun 插件开发人员,尝试通过一个开发者的角度尽可能全面地阐述一个 ChunJun 插件所经历的过程,同时消除开发者的困惑,快速上手插件开发。
从数据流的角度来看 ChunJun,可以理解为不同数据源的数据流通过对应的 ChunJun 插件处理,变成符合 ChunJun 数据规范的数据流;脏数据的处理可以理解为脏水流通过污水处理厂,变成符合标准,可以使用的水流,而对不能处理的水流收集起来。
插件开发不需要关注任务具体如何调度,只需要关注关键问题:
- 数据源本身读写数据的正确性;
- 如何合理且正确地使用框架;
- 配置文件的规范,每个插件都应有对应的配置文件;
每个插件应当有以下目录:
- conf:存放插件配置类的包。
- converter:存放插件数据类型转换规则类的包。
- source:存放插件数据源读取逻辑有关类的包。
- sink:存放插件数据源写入逻辑有关类的包。
- table:存放插件数据源 sql 模式有关类的包。
- util:存放插件工具类的包,chunjun 已经封装了一些常用工具类在 chunjun-core 模块中,如果还需编写插件工具类的请放在该插件目录中的 util 包。
一. Debug 调试
(1)本地调试
在 chunjun-local-test 模块中,官方已经写好了本地测试的 LocalTest 类,只需更改脚本文件路径,在代码处打上断点即可调试。

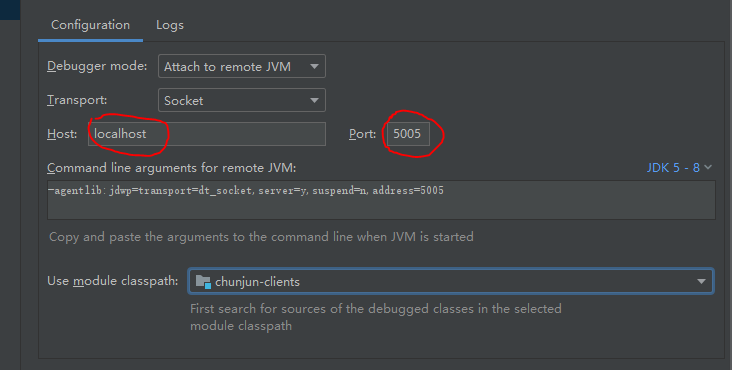
(2)远程调试
如果需要远程调试,那么需要在 flink-conf.yaml 中增加 Flink 的远程调试配置,然后在 idea 中配置”JVM Remote“,在代码块中打断点(这种方法还能调试 Flink 本身的代码)
env.java.opts.jobmanager: -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5005
env.java.opts.taskmanager: -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5006
只需要修改标记的这两个地方,如果是 HA 集群,需要根据日志修改怎么看日志,怎么修改,自行查资料。
至此,任务 idea 调试流程就这些内容。
二. sync(json)插件
以 Stream 插件为例:
(1) reader
插件数据源读取逻辑需要继承 BaseRichInputFormat 类,BaseRichInputFormat 是具体的输入数据的操作,包括 open、nextRecord、close,每个插件具体操作自己的数据,InputFormat 公共内容都在 BaseRichInputFormat,不要随意修改。
创建 StreamInputFormat 类继承 BaseRichInputFormat 类,重写其中的必要方法。
public class StreamInputFormat extends BaseRichInputFormat {
@Override
public InputSplit[] createInputSplitsInternal(int minNumSplits) {......}
@Override
public void openInternal(InputSplit inputSplit) {......}
@Override
public RowData nextRecordInternal(RowData rowData) throws ReadRecordException {......}
@Override
public boolean reachedEnd() {......}
@Override
protected void closeInternal() {......}
}
StreamInputFormat 类是通过 StreamInputFormatBuilder 类构建的。
public class StreamInputFormatBuilder extends BaseRichInputFormatBuilder<StreamInputFormat> {
private final StreamInputFormat format;
public StreamInputFormatBuilder() {
super.format = format = new StreamInputFormat();
}
@Override
protected void checkFormat() {......}
}
创建 StreamSourceFactory 继承 SourceFactory 类
public class StreamSourceFactory extends SourceFactory {
private final StreamConf streamConf;
public StreamSourceFactory(SyncConf config, StreamExecutionEnvironment env) {......}
@Override
public DataStream<RowData> createSource() {
StreamInputFormatBuilder builder = new StreamInputFormatBuilder();
builder.setStreamConf(streamConf);
AbstractRowConverter rowConverter;
if (useAbstractBaseColumn) {
rowConverter = new StreamColumnConverter(streamConf);
} else {
checkConstant(streamConf);
final RowType rowType =
TableUtil.createRowType(streamConf.getColumn(), getRawTypeConverter());
rowConverter = new StreamRowConverter(rowType);
}
builder.setRowConverter(rowConverter, useAbstractBaseColumn);
return createInput(builder.finish());
}
@Override
public RawTypeConverter getRawTypeConverter() {
return StreamRawTypeConverter::apply;
}
}
StreamColumnConverter 继承 AbstractRowConverter 类 是数据类型转换的具体实现,其中的方法参看源码。
接下来从作业执行角度阐述上述类之间的执行关系。
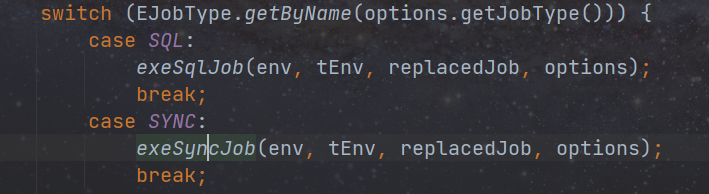
com.dtstack.chunjun.Main 入口类,通过判断启动参数来决定启动何种作业。
解析参数生成 SyncConf 对象,配置执行环境。

- .将上面解析生成的 SyncConf,然后通过反射加载具体的插件调用 createSource 方法生成 DataStream

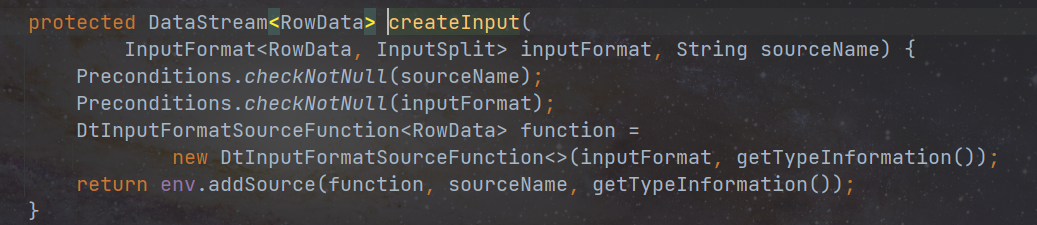
- createSource 方法中会构建 inputformat 对象,然后调用 createInput 方法,将 inputformat 对象封装至 DtInputFormatSourceFunction 中。
- DtInputFormatSourceFunction 类中会调用 inputformat 对象中的逻辑去读取数据,inputformat 中的 nextRecordInternal 方法读数据时,会对每条数据进行数据类型转换。
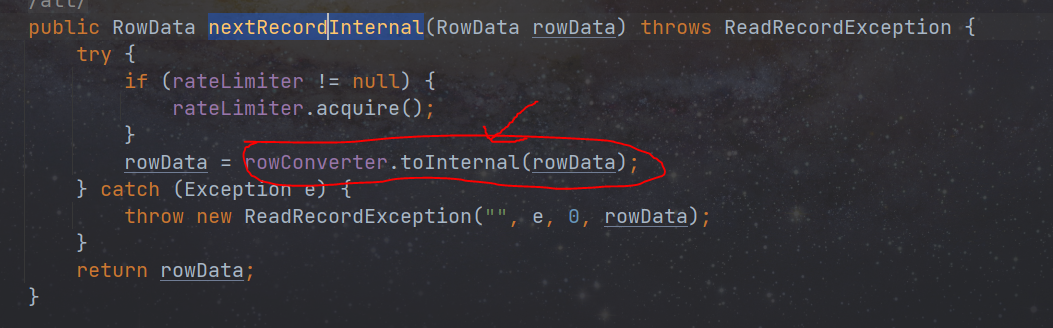
数据类型转换,flink 自己内部有一套自己的数据类型,用来和外部系统进行交互。交互过程分为:将外部系统数据按照定义的类型读入到 flink 内部、将外部数据转换成 flink 内部类型、将内部类型进行转换写到外部系统。所以每个插件需要有一套类型转换机制来满足数据交互的需求。
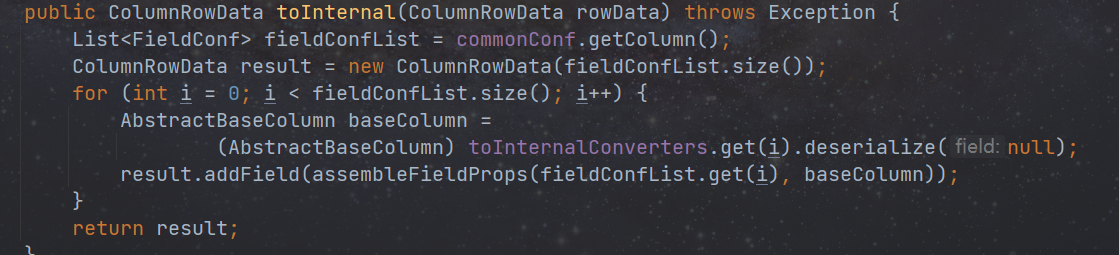
将外部数据转换成 flink 内部类,每个插件的转换方式都不同。
(2) writer
插件数据源读取逻辑需要继承 BaseRichOutputFormat 类,BaseRichOutputFormat 是具体的输入数据的操作,包括 open、writeRecord、close,每个插件具体操作自己的数据,OutputFormat 公共内容都在 BaseRichOutputFormat,不要随意修改。
创建 StreamOutputformat 类继承 BaseRichOutputformat 类,重写其中的必要方法。
public class StreamOutputFormat extends BaseRichOutputFormat {
//打开资源
@Override
protected void openInternal(int taskNumber, int numTasks) {......}
//写出单条数据
@Override
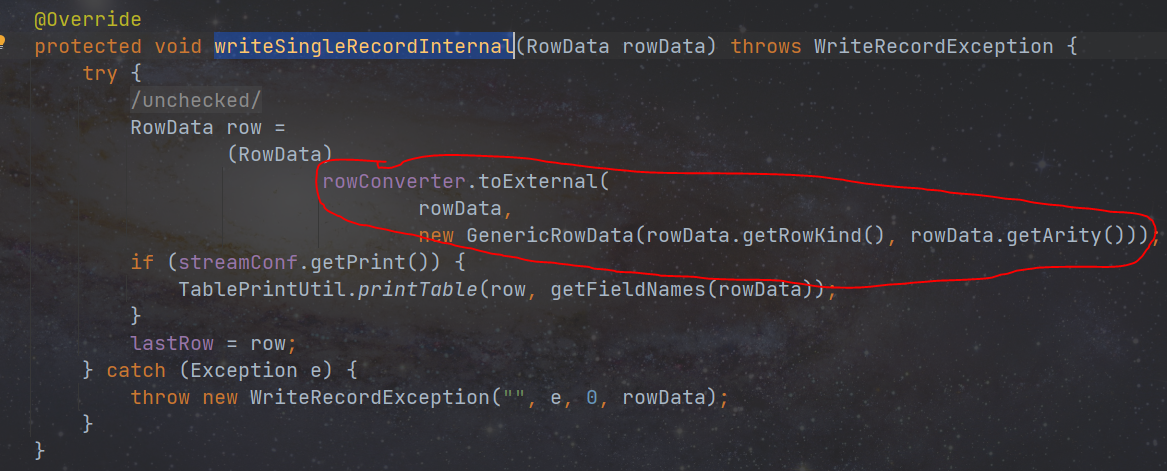
protected void writeSingleRecordInternal(RowData rowData) throws WriteRecordException {......}
//写出多条数据
@Override
protected void writeMultipleRecordsInternal() throws Exception {......}
//关闭资源
@Override
protected void closeInternal() {......}
}
StreamOutputFormat 类是通过 StreamOutputFormatBuilder 构建的
public class StreamOutputFormatBuilder extends BaseRichOutputFormatBuilder {
private StreamOutputFormat format;
public StreamOutputFormatBuilder() {
super.format = format = new StreamOutputFormat();
}
@Override
protected void checkFormat() {......}
}
创建 StreamSinkFactory 类继承 SinkFactory 类
public class StreamSinkFactory extends SinkFactory {
private final StreamConf streamConf;
public StreamSinkFactory(SyncConf config) {......}
@Override
public DataStreamSink<RowData> createSink(DataStream<RowData> dataSet) {
StreamOutputFormatBuilder builder = new StreamOutputFormatBuilder();
builder.setStreamConf(streamConf);
AbstractRowConverter converter;
if (useAbstractBaseColumn) {
converter = new StreamColumnConverter(streamConf);
} else {
final RowType rowType =
TableUtil.createRowType(streamConf.getColumn(), getRawTypeConverter());
converter = new StreamRowConverter(rowType);
}
builder.setRowConverter(converter, useAbstractBaseColumn);
return createOutput(dataSet, builder.finish());
}
@Override
public RawTypeConverter getRawTypeConverter() {
return StreamRawTypeConverter::apply;
}
}
接下来从作业执行角度阐述上述类之间的执行关系,在阐述 reader 插件执行步骤第三步时,通过反射加载具体的插件调用 createSource 方法生成 DataStream,同理,在生成 DataStream 后,writer 插件也是通过反射加载调用 createSink 方法生成 DataStreamSink 的。

- createSink 方法中会构建 outputformat 对象,然后调用 createoutput 方法,将 outputformat 对象封装至 DtOutputFormatSinkFunction 中。
- DtOutputFormatSinkFunction 类中会调用 outputformat 对象中的逻辑去写入数据,outputformat 中的 writeSingleRecordInternal 方法写入数据时,会对每条数据进行数据类型转换。
三. sql 插件
Flink SQL Connetor 详细设计文档参见FLIP-95
Flink SQL Connector 的架构简图如下所示:
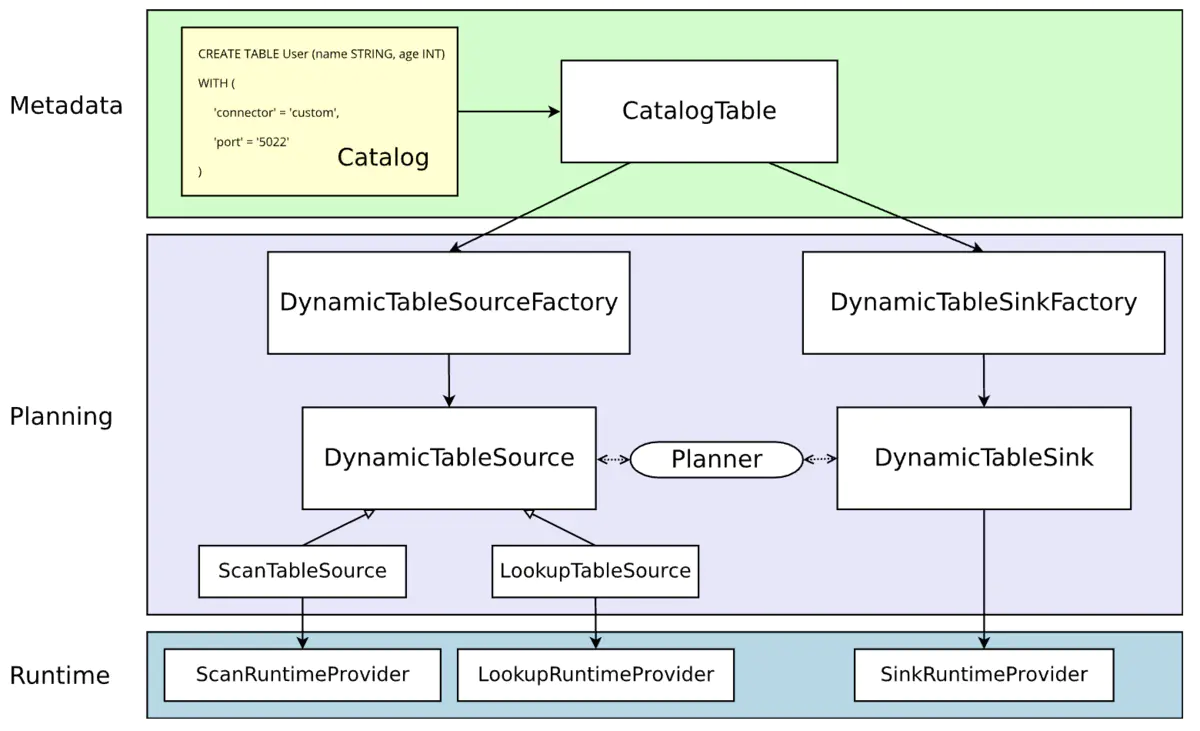
动态表一直都是 Flink SQL 流批一体化的重要概念,也是上述架构中 Planning 阶段的核心。而自定义 Connector 的主要工作就是实现基于动态表的 Source/Sink,还包括上游产生它的工厂,以及下游在 Runtime 阶段实际执行 Source/Sink 逻辑的 RuntimeProvider。
DynamicTableFactory 需要具备以下功能:
- 定义与校验建表时传入的各项参数;
- 获取表的元数据;
- 定义读写数据时的编码/解码格式(非必需);
- 创建可用的 DynamicTable[Source/Sink]实例。
DynamicTableSourceFactory:源表工厂,里面包含从 source 来的表(如:源表 kafka),从 lookup 来的表(如:维表 mysql)
DynamicTableSinkFactory:结果表工厂,里面包含从 sink 来的表(如:结果表 mysql)
DynamicTableSource:生成需要读取数据的 RichSourceFunction(面向流)\RichInputFormat(面向批,也可以用于流),实现 ScanTableSource 即可得到。生成需要读取数据的 TableFunction(全量)\AsyncTableFunction(lru),实现 LookupTableSource 即可。并被包装成 Provider。
DynamicTableSink:生成需要写出数据的 RichSinkFunction(面向流)\RichOutputFormat(面向批,也可以用于流)。并被包装成 Provider。
如果一个插件需要 source 端包含源表和维表,则实现 ScanTableSource 和 LookupTableSource 接口
如果一个插件需要 sink 端,则实现 DynamicTableSink 接口
实现了 DynamicTable[Source/Sink]Factory 接口的工厂类如下所示。
public class StreamDynamicTableFactory implements DynamicTableSourceFactory, DynamicTableSinkFactory {
@Override
public DynamicTableSource createDynamicTableSource(Context context) { }
@Override
public DynamicTableSink createDynamicTableSink(Context context) { }
@Override
public String factoryIdentifier() { }
@Override
public Set<ConfigOption<?>> requiredOptions() { }
@Override
public Set<ConfigOption<?>> optionalOptions() { }
}
- 根据 Connector 特性是否只用到 source、sink,实现对应的接口,这里以 stream 为例:既可以作为源表、又可以作为结果表,所以实现如下:

- 实现 createDynamicTableSource 方法用来创建 DynamicTableSource(ScanTableSource),在创建之前,我们可以利用内置的 TableFactoryHelper 工具类来校验传入的参数,当然也可以自己编写校验逻辑。另外,通过关联的上下文对象还能获取到表的元数据。
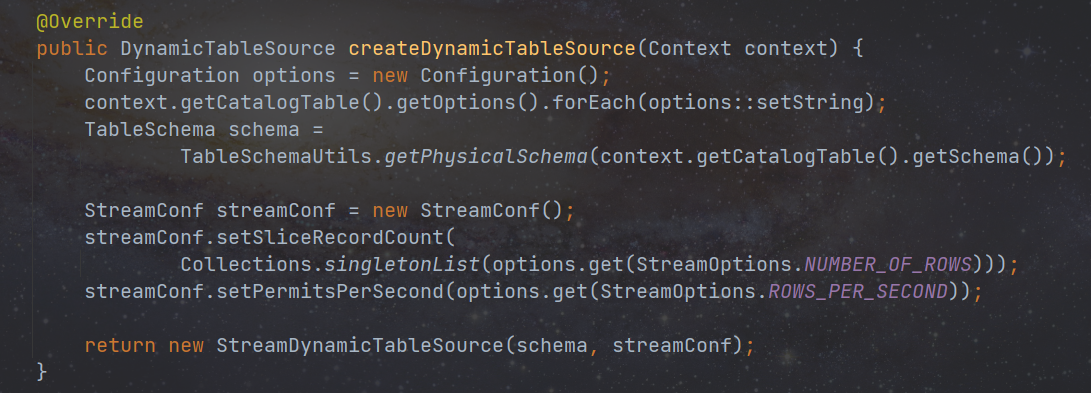
创建 StreamDynamicTableSource 类,目前 stream 实现了 ScanTableSource,实现 getScanRuntimeProvider 方法,用来创建 DtInputFormatSourceFunction(并创建 StreamInputFormat 包含在 DtInputFormatSourceFunction 中)
DtInputFormatSourceFunction:是所有 InputFormat 的包装类,里面实现类 2pc 等功能,不要随意修改。
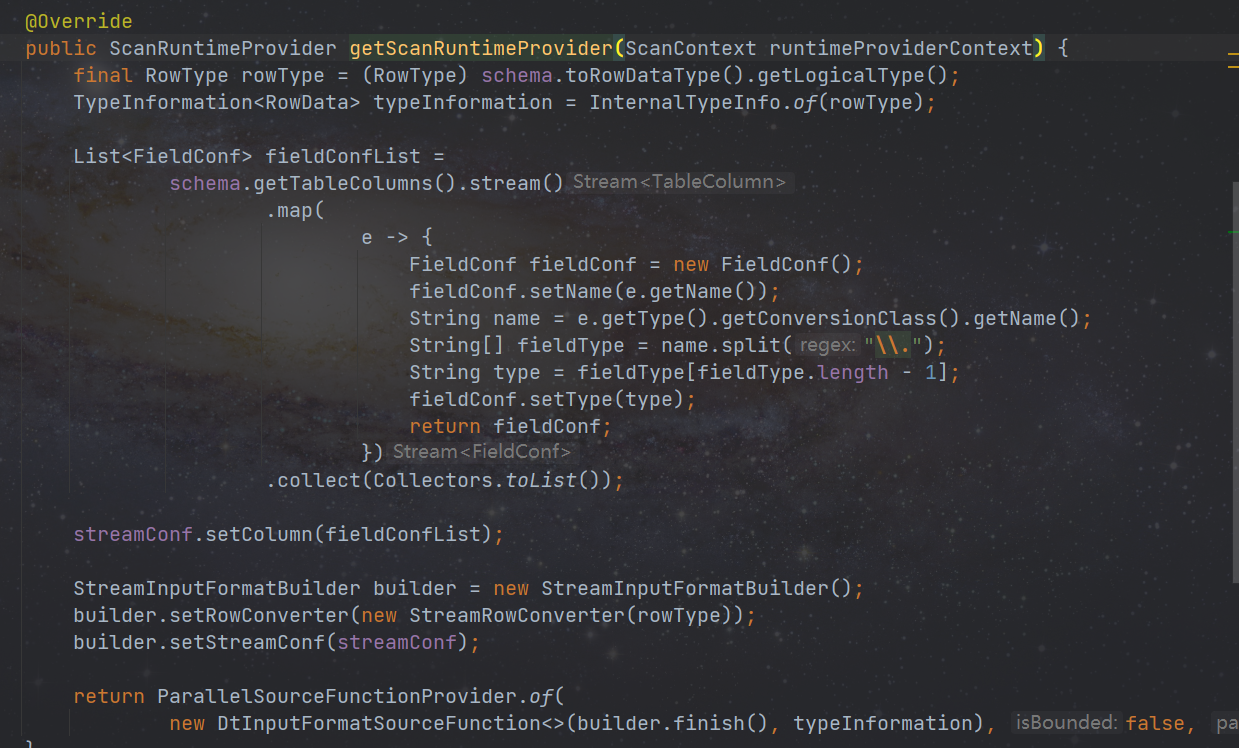
最后创建 StreamInputFormat,用来对数据的操作包括(open、writeRecord、close 方法),公共的内容已经抽取到了 BaseRichInputFormat 中,是所有 OutputFormat 的公共类,不要随意修改。
sink 类似。
插件也可按需求实现 LookupTableSource 类,以 jdbc 插件为例,实现 getLookupRuntimeProvider 方法,创建 JdbcLruTableFunction/JdbcAllTableFunction,
维表,支持全量和异步方式
全量缓存:将维表数据全部加载到内存中,建议数据量大不使用。
异步缓存:使用异步方式查询数据,并将查询到的数据使用lru缓存到内存中,建议数据量大使用。
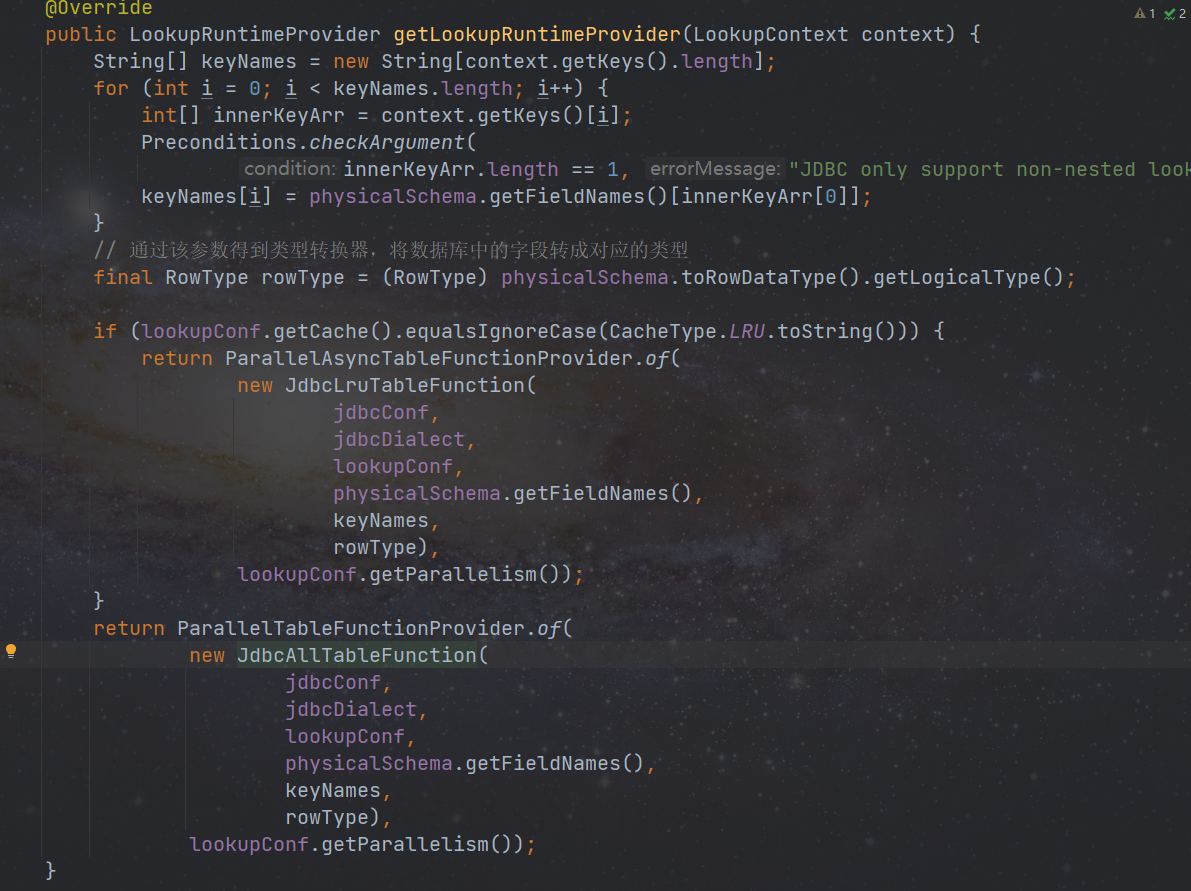
JdbcLruTableFunction 继承 AbstractLruTableFunction,重写其必要方法,JdbcAllTableFunction 继承 AbstractAllTableFunction,具体逻辑实现参考源码。
Flink SQL 采用 SPI 机制来发现与加载表工厂类。所以最后不要忘了 classpath 的 META-INF/services 目录下创建一个名为org.apache.flink.table.factories.Factory的文件,并写入我们自定义的工厂类的全限定名,如:com.dtstack.chunjun.connector.stream.table.StreamDynamicTableFactory
四. 插件打包
进入项目根目录,使用 maven 打包,有关打包配置请参考其他插件的 pom 文件。
mvn clean package -DskipTests
打包之前注意代码格式,在项目根目录执行以下命令格式化代码。
mvn spotless:apply
打包结束后,项目根目录下会产生 chunjun-dist 目录,如果没意外的话,您开发的插件会在 connetor 目录下,之后就可以提交开发平台测试啦!