
ChunJun Oracle LogMiner 实时采集基本原理
本文主要对 Logminer 基本原理以及如何使用和 ChunJun 与 Logminer 的集成进行介绍 通过本文你可以了解到:
- Logminer 是什么
- Logminer 的使用
- ChunJun 如何和 Logminer 的集成
Logminer 是什么?
LogMiner 是 Oracle 公司从产品 8i 以后提供的一个实际非常有用的分析工具,使用该工具可以轻松获得 Oracle 重做日志文件(归档日志文件)中的具体内容,LogMiner 分析工具实际上是由一组 PL/SQL 包和一些动态视图组成,它作为 Oracle 数据库的一部分来发布,是 oracle 公司提供的一个完全免费的工具。
具体的说: 对用户数据或数据库字典所做的所有更改都记录在 Oracle 重做日志文件 RedoLog 中,Logminer 就是一个解析 RedoLog 的工具,通过 Logminer 解析 RedoLog 可以得到对应的 SQL 数据。
Oracle 中的 RedoLog 写入流程: Oracle 重做日志采用循环写入的方式,每一个 Oracle 实例至少拥有2 组日志组。Oracle 重做日志一般由 Oracle 自动切换,重做日志文件在当 LGWR 进程停止写入并开始写入下一个日志组时发生切换,或在用户收到发出 ALTER SYSTEM SWITCH LOGFILE 时发生切换。如果 Oracle 数据库开启了归档功能,则在日志组发生切换的时候,上一个日志组的日志文件会被归档到归档目录里
从上面可知 Oracle 里的 RedoLog 文件分为两种:
- 当前写的日志组的文件,可通过 v$log 和 v$logfile 得到
- 归档的 redoLog 文件,可通过 v$archived_log 得到
v$log 文档 https://docs.oracle.com/cd/B19306_01/server.102/b14237/dynviews_1150.htm#REFRN30127
v$logfile 文档 https://docs.oracle.com/cd/B28359_01/server.111/b28320/dynviews_2031.htm#REFRN30129
v$archived_log 文档 https://docs.oracle.com/cd/E18283_01/server.112/e17110/dynviews_1016.htm
通过循环查找到最新符合要求的 RedoLog 并让 Logminer 加载分析,分析的数据在视图 v$logmnr_contents 里,通过读取 v$logmnr_contents 就可以得到 Oracle 的实时数据
Logminer 的使用
Logminer 的配置与开启
Logminer 的使用
指定 LogMiner 字典。
指定重做日志文件列表以进行分析。 使用
DBMS_LOGMNR.ADD_LOGFILE过程,或指示 LogMiner 在启动 LogMiner 时自动创建要分析的日志文件列表(在步骤 3 中)。启动 LogMiner。 使用
DBMS_LOGMNR.START_LOGMNR程序。请求感兴趣的重做数据。 查询
V$LOGMNR_CONTENTS视图。(您必须具有SELECT ANY TRANSACTION查询此视图的权限)结束 LogMiner 会话。 使用
DBMS_LOGMNR.END_LOGMNR程序
Logminer 字典
LogMiner 字典作用
Oracle 数据字典记录当前所有表的信息,字段的信息等等。LogMiner 使用字典将内部对象标识符和数据类型转换为对象名称和外部数据格式。如果没有字典,LogMiner 将返回内部对象 ID,并将数据显示为二进制数
INSERT INTO HR.JOBS(JOB_ID, JOB_TITLE, MIN_SALARY, MAX_SALARY) VALUES('IT_WT','Technical Writer', 4000, 11000);
没有字典,LogMiner 将显示:
insert into "UNKNOWN"."OBJ# 45522"("COL 1","COL 2","COL 3","COL 4") values
(HEXTORAW('45465f4748'),HEXTORAW('546563686e6963616c20577269746572'),
HEXTORAW('c229'),HEXTORAW('c3020b'));
Logminer 字典选项
LogMiner 字典的选项支持三种:
Using the Online Catalog Oracle recommends that you use this option when you will have access to the source database from which the redo log files were created and when no changes to the column definitions in the tables of interest are anticipated. This is the most efficient and easy-to-use option.
Extracting a LogMiner Dictionary to the Redo Log Files Oracle recommends that you use this option when you do not expect to have access to the source database from which the redo log files were created, or if you anticipate that changes will be made to the column definitions in the tables of interest.
Extracting the LogMiner Dictionary to a Flat File This option is maintained for backward compatibility with previous releases. This option does not guarantee transactional consistency. Oracle recommends that you use either the online catalog or extract the dictionary from redo log files instead.
翻译:
使用在线目录 当您可以访问从其创建重做日志文件的源数据库并且预计不会对目标表中的列定义进行任何更改时,Oracle 建议您使用此选项。这是最有效和易于使用的选项。
将 LogMiner 字典提取到重做日志文件 如果您不希望访问创建重做日志文件的源数据库,或者希望对感兴趣的表中的列定义进行更改,则 Oracle 建议您使用此选项。
将 LogMiner 字典提取到平面文件 维护此选项是为了与以前的版本向后兼容。此选项不能保证事务的一致性。Oracle 建议您使用联机目录或从重做日志文件中提取字典。
指定 Logminer 重做日志文件
要启动新的重做日志文件列表,需要使用 DBMS_LOGMNR.NEW 以表明这是新列表的开始
EXECUTE DBMS_LOGMNR.ADD_LOGFILE(
LOGFILENAME => '/oracle/logs/log1.f',
OPTIONS => DBMS_LOGMNR.NEW);
可以使用下列语句额外再添加日志文件
EXECUTE DBMS_LOGMNR.ADD_LOGFILE(
LOGFILENAME => '/oracle/logs/log2.f',
OPTIONS => DBMS_LOGMNR.ADDFILE);
启动 LogMiner
使用 DBMS_LOGMNR.START_LOGMN 启动 Logminer。可以指定参数:
指定 LogMiner 如何过滤返回的数据(例如,通过开始和结束时间或 SCN 值)
指定用于格式化 LogMiner 返回的数据的选项
指定要使用的 LogMiner 词典
主要的参数有:
OPTIONS参数说明:
* DBMS_LOGMNR.SKIP_CORRUPTION - 跳过出错的redlog
* DBMS_LOGMNR.NO_SQL_DELIMITER - 不使用 ';'分割redo sql
* DBMS_LOGMNR.NO_ROWID_IN_STMT - 默认情况下,用于UPDATE和DELETE操作的SQL_REDO和SQL_UNDO语句在where子句中包含“ ROWID =”。
* 但是,这对于想要重新执行SQL语句的应用程序是不方便的。设置此选项后,“ ROWID”不会放置在重构语句的末尾
* DBMS_LOGMNR.DICT_FROM_ONLINE_CATALOG - 使用在线字典
* DBMS_LOGMNR.CONTINUOUS_MINE - 需要在生成重做日志的同一实例中使用日志
* DBMS_LOGMNR.COMMITTED_DATA_ONLY - 指定此选项时,LogMiner将属于同一事务的所有DML操作分组在一起。事务按提交顺序返回。
* DBMS_LOGMNR.STRING_LITERALS_IN_STMT - 默认情况下,格式化格式化的SQL语句时,SQL_REDO和SQL_UNDO语句会使用数据库会话的NLS设置
* 例如NLS_DATE_FORMAT,NLS_NUMERIC_CHARACTERS等)。使用此选项,将使用ANSI / ISO字符串文字格式对重构的SQL语句进行格式化。
示例
EXECUTE DBMS_LOGMNR.START_LOGMNR(
STARTTIME => '01-Jan-2003 08:30:00',
ENDTIME => '01-Jan-2003 08:45:00',
OPTIONS => DBMS_LOGMNR.DICT_FROM_ONLINE_CATALOG +
DBMS_LOGMNR.CONTINUOUS_MINE);
在 V$ LOGMNR_CONTENTS 中查询感兴趣的重做数据
Logminer 会解析 redoLog 里的日志加载到 v$LOGMNR_CONTENTS 视图里,我们只需要使用 sql查询 即可获取对应数据 v$LOGMNR_CONTENTS 视图相关字段 https://docs.oracle.com/cd/B19306_01/server.102/b14237/dynviews_1154.htm
主要字段有:
| 列 | 数据类型 | 描述 |
|---|---|---|
| SCN | NUMBER | oracle 为每个已提交的事务分配唯一的 scn |
| OPERATION | VARCHAR2(32) | INSERT UPDATE DELETE DDL COMMIT ROLLBACK..... |
| SEG_OWNER | VARCHAR2(32) | schema |
| TABLE_NAME | VARCHAR2(32) | 表名 |
| TIMESTAMP | DATE | 数据库变动时间戳 |
| SQL_REDO | VARCHAR2(4000) | 重建的 SQL 语句,该语句等效于进行更改的原始 SQL 语句 |
示例
SELECT
scn,
timestamp,
operation,
seg_owner,
table_name,
sql_redo,
row_id,
csf
FROM
v$logmnr_contents
WHERE
scn > ?
查询出来的数据示例:
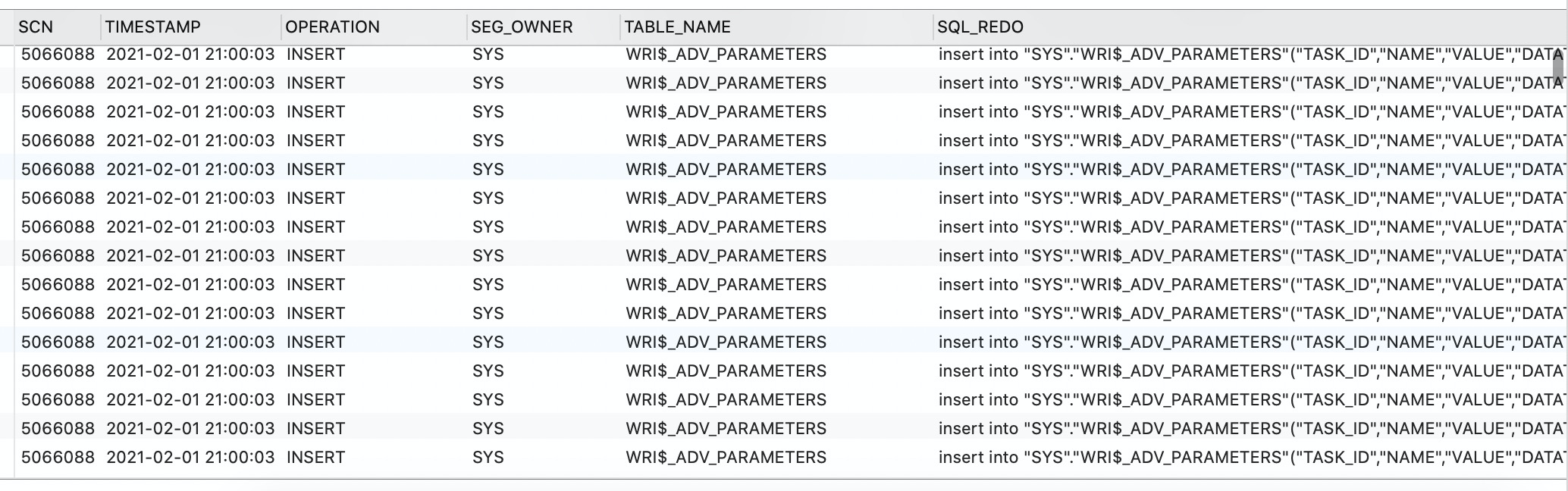
ChunJun 如何使用 Logminer
使用 Logminer 在于关键 2 步骤:
- 找到需要分析的 Redolog 日志,加载到 Logminer
- 开启 Logminer,在 v$LOGMNR_CONTENTS 查询感兴趣数据
1. 查找 RedoLog 文件
从上面介绍中 我们可以知道 Redolog 来源于日志组和归档日志里,所以 ChunJun 根据 SCN 号查询日志组以及归档日志获取到对应的文件
SELECT
MIN(name) name,
first_change#
FROM
(
SELECT
MIN(member) AS name,
first_change#,
281474976710655 AS next_change#
FROM
v$log l
INNER JOIN v$logfile f ON l.group# = f.group#
WHERE l.STATUS = 'CURRENT' OR l.STATUS = 'ACTIVE'
GROUP BY
first_change#
UNION
SELECT
name,
first_change#,
next_change#
FROM
v$archived_log
WHERE
name IS NOT NULL
)
WHERE
first_change# >= ?
OR ? < next_change#
GROUP BY
first_change#
ORDER BY
first_change#
查询出来的数据示例:
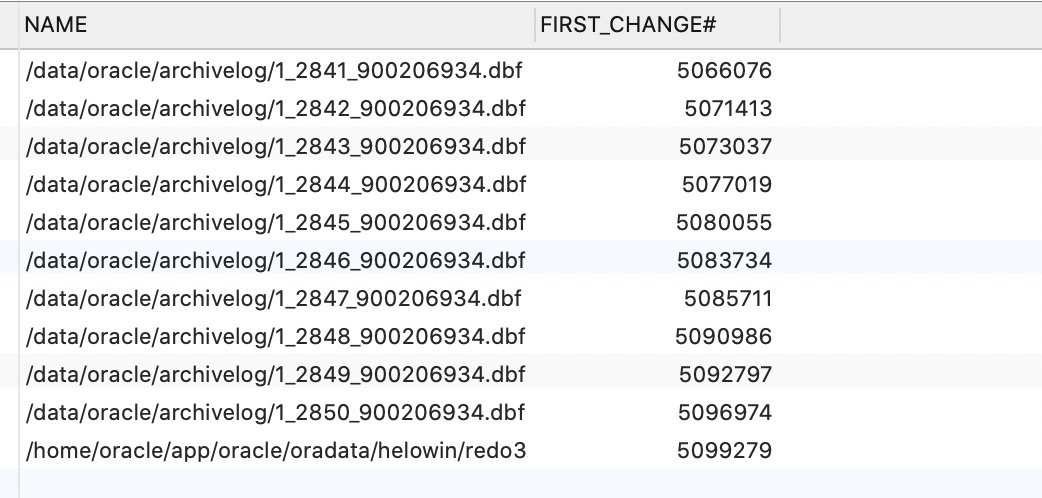
注意: 如果 Logminer 的处理速度比 Oracle 产生数据速度快,那么理论上 ChunJun 只需要加载日志组文件不需要加载归档日志文件,而 Logminer 加载文件会比较消耗资源,所以会先进行 RedoLog 文件的查找,如果本次查找的文件和上次的没有区别,说明 Logminer 不需要加载新的日志文件,只需要重新再从视图里查询数据即可
2. 加载文件到 Logminer
通过一个存储过程 查询到日志文件之后 加载到 Logminer 里 并开启 Logminer
DECLARE
st BOOLEAN := true;
start_scn NUMBER := ?;
BEGIN
FOR l_log_rec IN (
SELECT
MIN(name) name,
first_change#
FROM
(
SELECT
MIN(member) AS name,
first_change#,
281474976710655 AS next_change#
FROM
v$log l
INNER JOIN v$logfile f ON l.group# = f.group#
WHERE l.STATUS = 'CURRENT' OR l.STATUS = 'ACTIVE'
GROUP BY
first_change#
UNION
SELECT
name,
first_change#,
next_change#
FROM
v$archived_log
WHERE
name IS NOT NULL
)
WHERE
first_change# >= start_scn
OR start_scn < next_change#
GROUP BY
first_change#
ORDER BY
first_change#
) LOOP IF st THEN
SYS.DBMS_LOGMNR.add_logfile(l_log_rec.name, SYS.DBMS_LOGMNR.new);
st := false;
ELSE
SYS.DBMS_LOGMNR.add_logfile(l_log_rec.name);
END IF;
END LOOP;
SYS.DBMS_LOGMNR.start_logmnr( options => SYS.DBMS_LOGMNR.skip_corruption + SYS.DBMS_LOGMNR.no_sql_delimiter + SYS.DBMS_LOGMNR.no_rowid_in_stmt
+ SYS.DBMS_LOGMNR.dict_from_online_catalog + SYS.DBMS_LOGMNR.string_literals_in_stmt );
END;
3. 查询数据
SELECT
scn,
timestamp,
operation,
seg_owner,
table_name,
sql_redo,
row_id,
csf
FROM
v$logmnr_contents
WHERE
scn > ?
ChunJun 就是在一个循环里 执行上述 sql 语句查询数据。 查询日志文件,加载到 logminer,开启 logminer,读取数据,更新当前最新 SCN 号,当数据读取完毕,代表本次加载的日志文件加载完了,通过 SCN 号寻找后续日志文件,重复上述操作
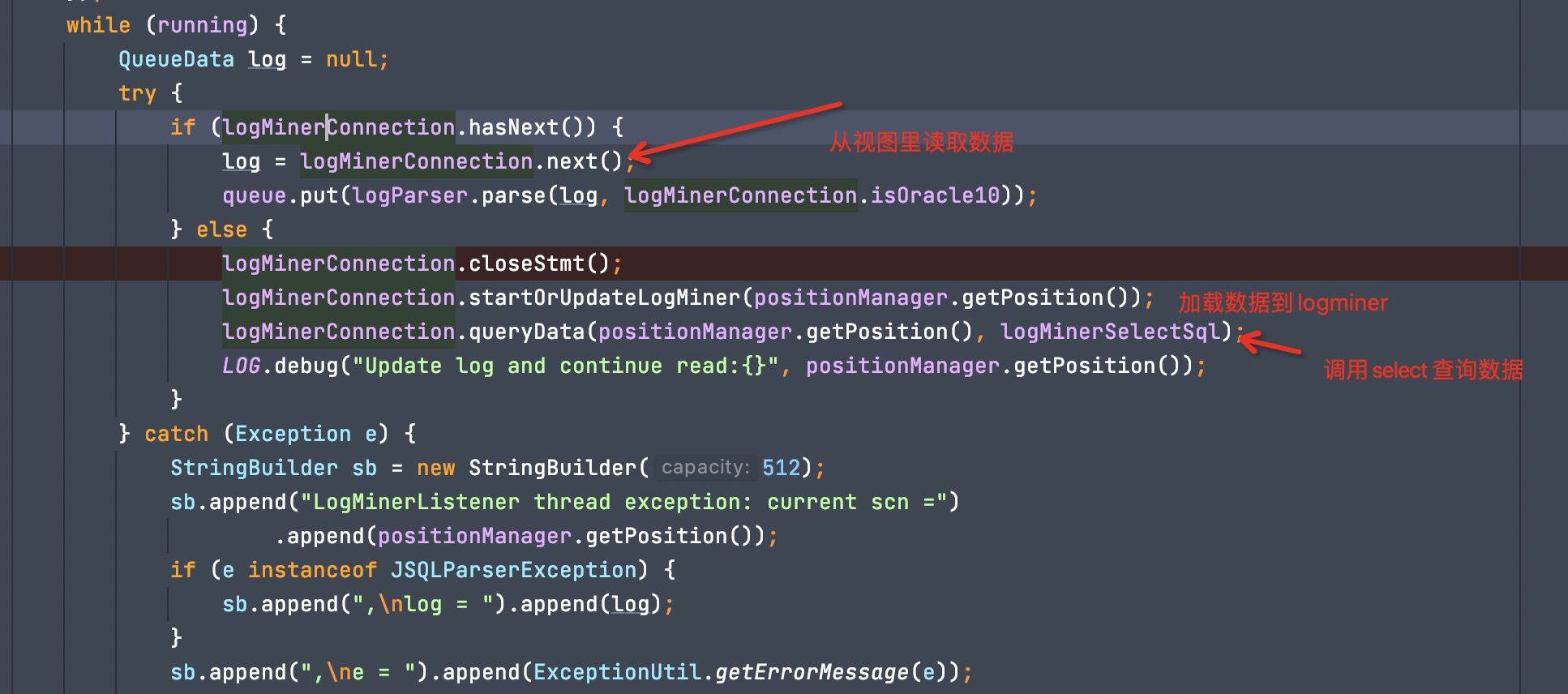
从 v$logmnr_contents 获取到数据之后,ChunJun 使用 net.sf.jsqlparser.parser.CCJSqlParserUtil 来解析 sql_redo 值 获取到的 sql_redo 语句格式示例:
insert into "TUDOU"."CDC"("ID","USER_ID","NAME","date1") values ('19','1','b',TO_DATE('2021-01-29 11:25:50', 'YYYY-MM-DD HH24:MI:SS'))
使用 net.sf.jsqlparser.parser.CCJSqlParserUtil 解析上述 SQL 获取各个字段的值
Oracle10 和 Oracle11 的部分区别
- v$LOGMNR_CONTENTS 里 Oracle10 比 Oracle11 少了 commit_scn 字段
- 日志组字段里没有 next_change#字段
- 如果 Sql 里含有 ToDate 函数,Logminer10 的 sql_redo 加载的是 ToDate 函数日期格式默认是 DD-MON-RR 格式,而 Logminer11 则是 Todate 函数执行后的值,所以 Logminer10 会在获取连接的时候,执行下列 SQL,设置日期格式,ChunJun 再对其进行正则匹配,替换得到最终的值。
//修改当前会话的date日期格式
public final static String SQL_ALTER_DATE_FORMAT ="ALTER SESSION SET NLS_DATE_FORMAT = 'YYYY-MM-DD HH24:MI:SS'";
//修改当前会话的timestamp日期格式
public final static String NLS_TIMESTAMP_FORMAT ="ALTER SESSION SET NLS_TIMESTAMP_FORMAT = 'YYYY-MM-DD HH24:MI:SS.FF6'";

