What is incremental mode
The incremental mode mainly applies to some Insert only tables. As the service grows, a large amount of data is stored in the table. If the entire table is synchronized every time, it will consume more time and resources. Therefore, you need an incremental mode feature that reads only incremental portions of the data at a time.
Principle
The incremental mode works by combining the increColumn with the filter criteria in the SQL statement of the query, such as where ID >? To filter out the data that has been read before.
Incremental mode is for two or more synchronous jobs. For jobs that perform incremental mode for the first time, which are actually full table synchronization, incremental mode differs from other jobs in that an endLocation metric is recorded after the job is executed and uploaded to Prometheus for subsequent use. Except for the first job, all subsequent incremental mode jobs take the endLocation of the previous job as the filter basis (startLocation) for this job. For example, after the first job is executed and endLocation is 10, the next job will build SQL statements such as SELECT ID,name,age from table where ID > 10 to achieve incremental read.
increColumn:Incrementally increasing a field in a database table, such as a self-increment ID
Limit
- Only RDB Reader plugins can be used
- It is implemented by building SQL filtering statements and therefore can only be used with RDB plugins
- Incremental synchronization only cares about reads, not writes, and is therefore only relevant to reader plugins
- Incremental fields can only be of numeric type and time type
- Indicators need to be uploaded to Prometheus, which does not support string types and therefore only supports data types and time types. The time type is converted to a timestamp and uploaded
- The value of the increColumn can be repeated, but must be incremented
- Because of the use of '>', the field is required to be incremented.
How to handle increColumn repetition scenarios
Consider a scenario in which the endLocation of an incremental mode is X, and data with the value of the delta key =x is written to the table in the interval between the start of the next incremental mode. By default, if the increment key is id, the next operation will concatenate such as SELECT ID,name,age FROM table WHERE ID > x. The data inserted in the gap with id=x will be lost. To correspond to the above scenario, chunjun incremental mode provides the configuration item useMaxFunc (default is false). When setting useMaxFunc=true, Chunjun gets the maximum value of the increment key in the current database as the endLocation for the job when the increment job starts, and changes the operation symbol used for startLocation from '>' to '>='. Such as:
- The SQL statement will be concatenated if the endLocation of the last job is 10 and the maximum ID is 100 when an increment is started
- SELECT id,name,age FROM table WHERE id >= 10 AND id < 100
- When the next increment job starts with a maximum ID of 200, the SQL statement will be concatenated
- SELECT id,name,age FROM table WHERE id >=100 AND id < 200
How to use incremental mode
Environment prepare
Because Prometheus is used to collect indicator information, Prometheus and PushGateway must be installed first.
Download the Flink Metric Prometheus dependency and place it in the Flink Lib directory
Modify Flink configuration file conf/flink-conf.yaml to add Flink metric configuration
metrics.reporter.promgateway.host: host01
metrics.reporter.promgateway.port: 9091
metrics.reporter.promgateway.deleteOnShutdown: false
metrics.reporter.promgateway.class: org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter
json example
The main configuration items are increColumn and startLocation
Mysql is used as an example:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
},
{
"name": "age",
"type": "int"
}
],
"customSql": "",
"increColumn": "id", //Specify an increColumn for incremental mode. The increColumn must be a field that exists for column
"startLocation": "2", //Null for the first execution, configurable as a string or not, and subsequent submitted jobs use the values indicated in Prometheus
"username": "root",
"password": "root",
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://localhost:3306/test?useSSL=false"
],
"table": [
"baserow"
]
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": false
}
}
}
],
"setting": {
"restore": {
"restoreColumnName": "id"
},
"speed": {
"channel": 1,
"bytes": 0
}
}
}
}
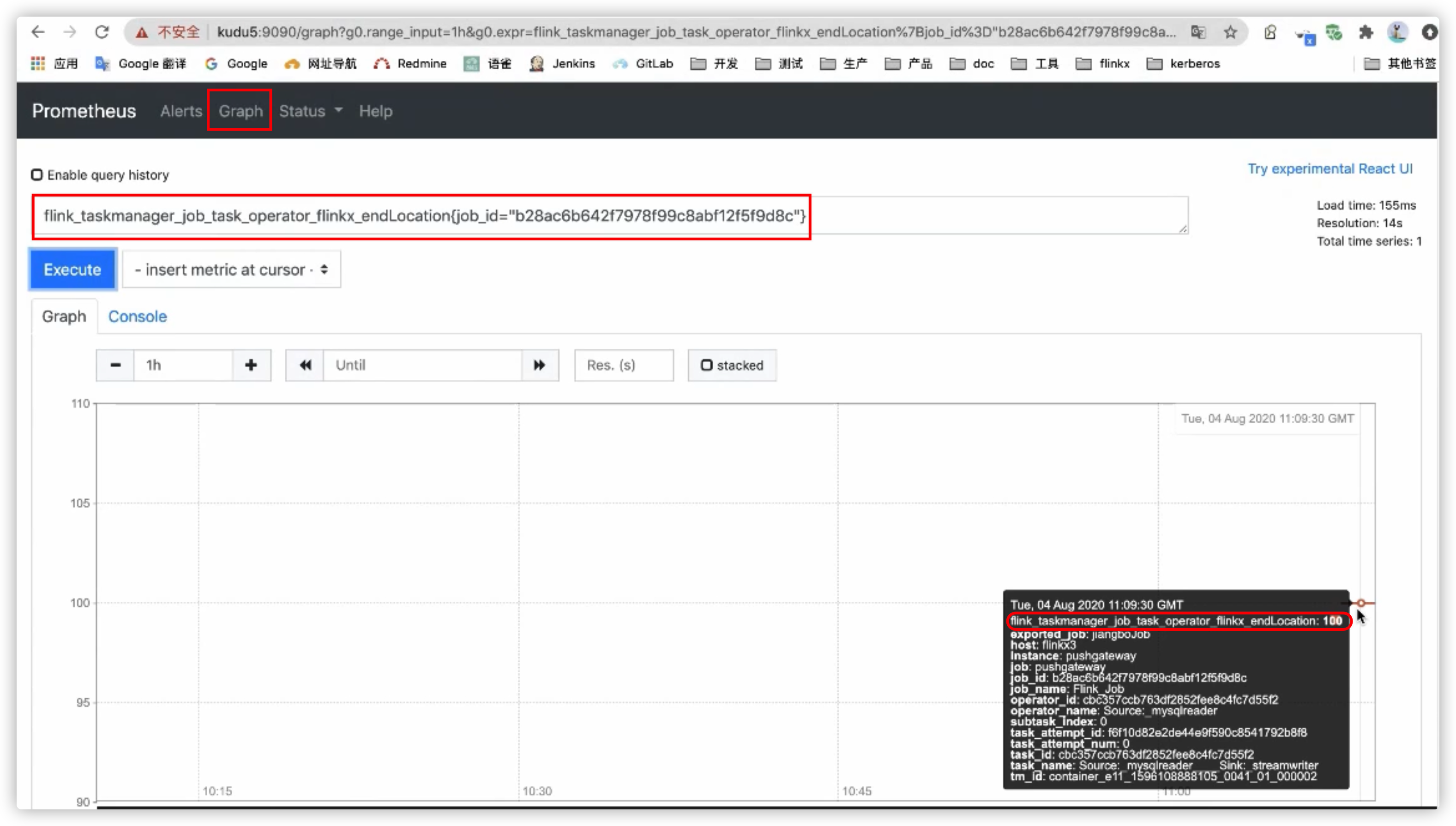
Query in prometheus
Query the endLocation indicator value in Prometheus using the JobId corresponding to the Flink job
flink_taskmanager_job_task_operator_flinkx_endlocation{job_id="xxx"}